Running on HPC Systems¶
libEnsemble has been tested on systems of highly varying scales, from laptops to thousands of compute nodes. On multi-node systems, there are a few alternative ways of configuring libEnsemble to run and launch tasks (i.e., user applications) on the available nodes.
The Forces tutorial gives an example with a simple MPI application.
Note that while the diagrams below show one application being run per node, configurations with multiple nodes per worker or multiple workers per node are both common use cases.
Centralized Running¶
The default communications scheme places the manager and workers on the first node. The MPI Executor can then be invoked by each simulation worker, and libEnsemble will distribute user applications across the node allocation. This is the most common approach where each simulation runs an MPI application.
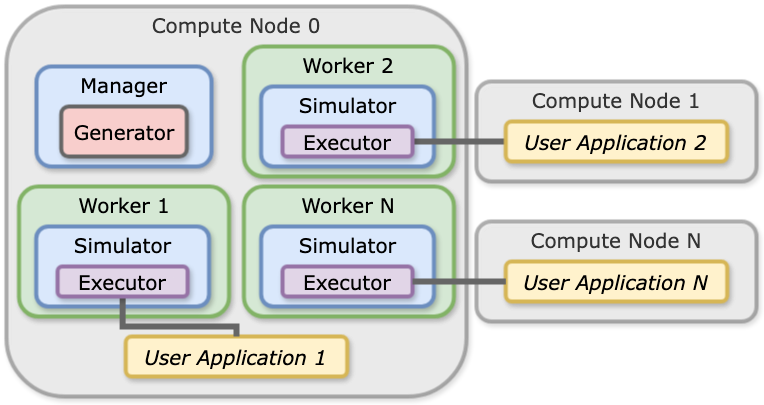
A SLURM batch script may include:
#SBATCH --nodes 3
python run_libe_forces.py --nworkers 3
If running multiple generator processes instead, then set the libE_specs option gen_on_worker so that multiple worker processes can run multiple generator instances.
Dedicated Mode¶
If the libE_specs option dedicated_mode is set to True, the MPI executor will not launch applications on nodes where libEnsemble Python processes (manager and workers) are running. Workers launch applications onto the remaining nodes in the allocation.
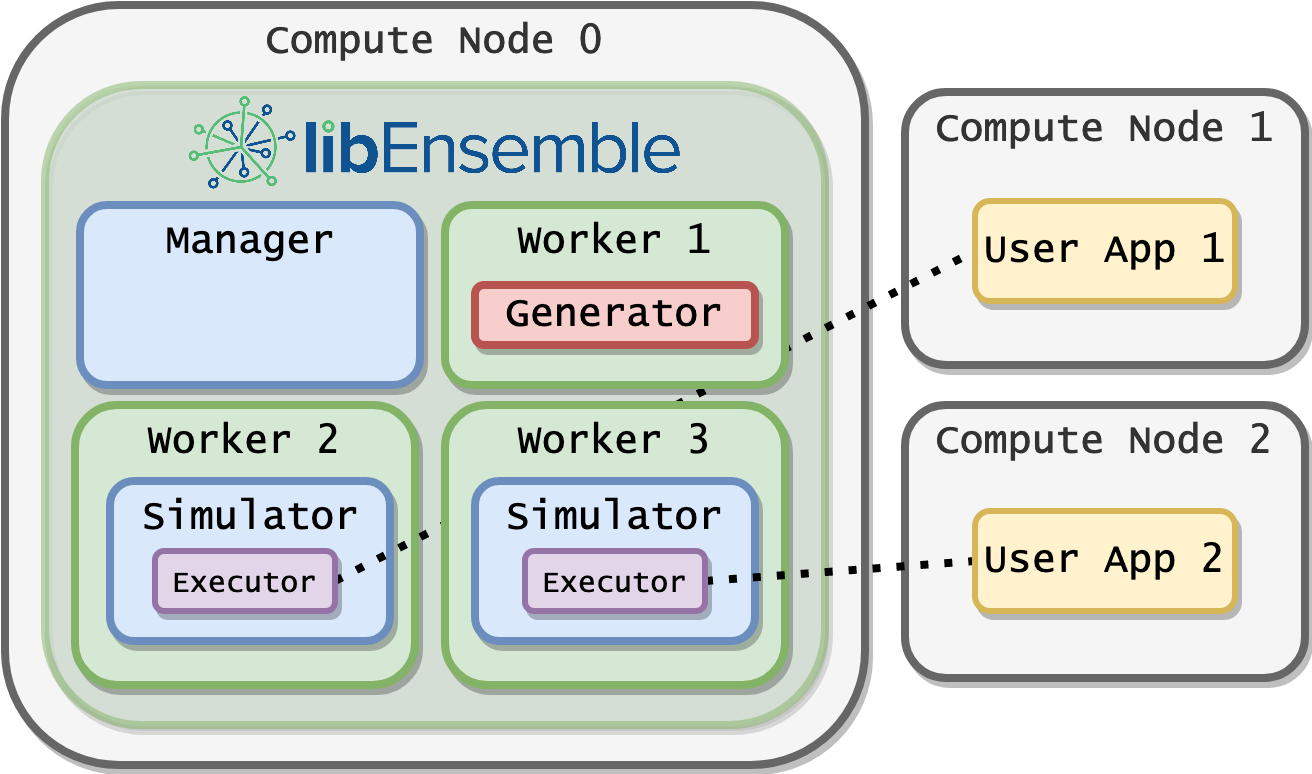
In calling script:
1ensemble.libE_specs = LibeSpecs(
2 gen_on_worker=True,
3 num_resource_sets=2,
4 dedicated_mode=True,
5)
A SLURM batch script may include:
#SBATCH --nodes 3
python run_libe_forces.py --nworkers 3
Distributed Running¶
In the distributed approach, libEnsemble can be run using the mpi4py communicator, with workers distributed across nodes. This is most often used when workers run simulation code directly, via a Python interface. The user script is invoked with an MPI runner, for example (using an mpich-based MPI):
mpirun -np 4 -ppn 1 python myscript.py
The distributed approach, can also be used with the executor, to co-locate workers with the applications they submit. Ensuring that workers are placed as required in this case requires a careful MPI rank placement.
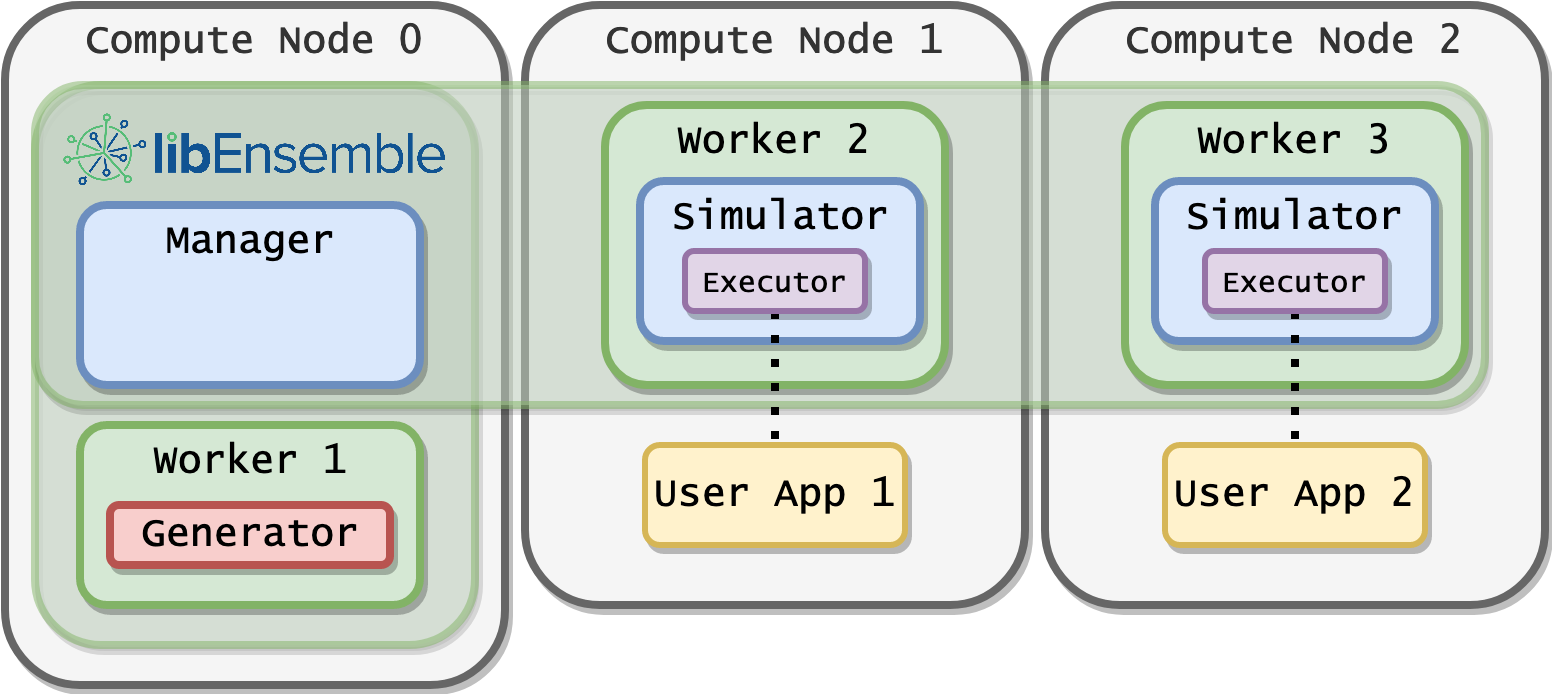
This allows the libEnsemble worker to read files produced by the application on local node storage.
Configuring the Run¶
On systems with a job scheduler, libEnsemble is typically run within a single job submission. All user simulations will run on the nodes within that allocation.
How does libEnsemble know where to run tasks (user applications)?
The libEnsemble MPI Executor can be initialized from the user calling script, and then used by workers to run tasks. The Executor will automatically detect the nodes available on most systems. Alternatively, the user can provide a file called node_list in the run directory. By default, the Executor will divide up the nodes evenly to each worker.
Mapping Tasks to Resources¶
The resource manager detects node lists from common batch schedulers, and partitions these to workers. The MPI Executor accesses the resources available to the current worker when launching tasks.
Assigning GPUs¶
libEnsemble automatically detects and assigns Nvidia, AMD, and Intel GPUs without modifying the user scripts. This automatically works on many systems, but if the assignment is incorrect or needs to be modified the user can specify platform information. The forces_gpu tutorial shows an example of this.
Varying resources¶
libEnsemble also features dynamic resource assignment, whereby the number of processes and/or the number of GPUs can be a set for each simulation by the generator.
Overriding Auto-Detection¶
libEnsemble can automatically detect system information. This includes resource information, such as available nodes and the number of cores on the node, and information about available MPI runners.
System detection for resources can be overridden using the resource_info libE_specs option.
When using the MPI Executor, it is possible to override the detected information using the custom_info argument. See the MPI Executor for more.
Systems with Launch/MOM Nodes¶
Some large systems have a 3-tier node setup. That is, they have a separate set of launch nodes
(known as MOM nodes on Cray Systems). User batch jobs or interactive sessions run on a launch node.
Most such systems supply a special MPI runner that has some application-level scheduling
capability (e.g., aprun, jsrun). MPI applications can only be submitted from these nodes.
There are two ways of running libEnsemble on these kinds of systems. The first, and simplest, is to run libEnsemble on the launch nodes. This is often sufficient if the worker’s simulation or generation functions are not doing much work (other than launching applications). This approach is inherently centralized. The entire node allocation is available for the worker-launched tasks.
However, running libEnsemble on the compute nodes is potentially more scalable and will better manage simulation and generation functions that contain considerable computational work or I/O. Therefore the second option is to use Globus Compute to isolate this work from the workers.
Globus Compute - Remote User Functions¶
If libEnsemble is running on some resource with internet access (laptops, login nodes, other servers, etc.), workers can be instructed to launch generator or simulator user function instances to separate resources from themselves via Globus Compute (formerly funcX), a distributed, high-performance function-as-a-service platform:
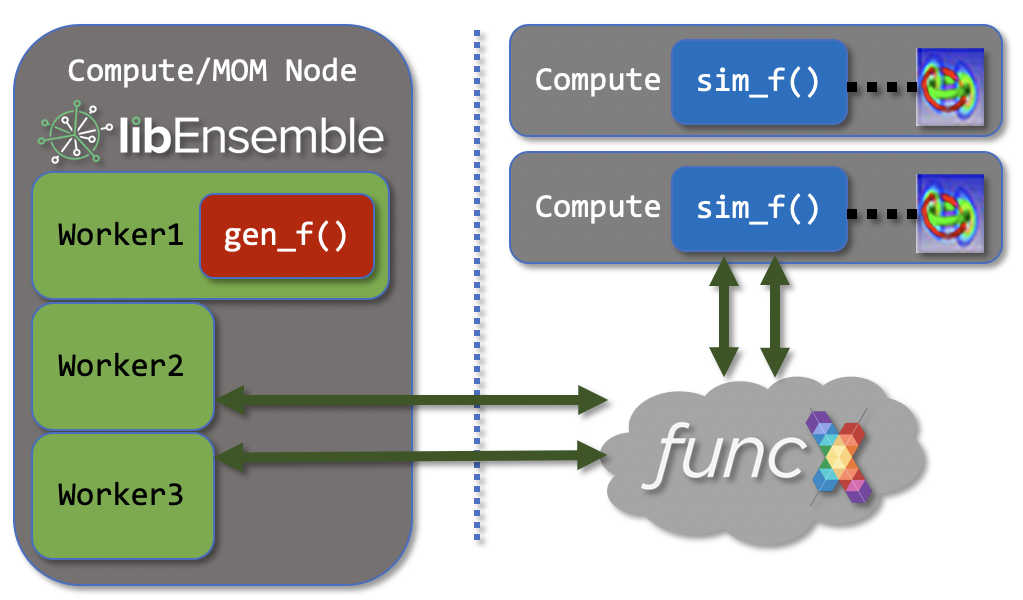
This is useful for running ensembles across machines and heterogeneous resources, but comes with several caveats:
User functions registered with Globus Compute must be non-persistent, since manager-worker communicators can’t be serialized or used by a remote resource.
Likewise, the
Executor.manager_poll()capability is disabled. The only available control over remote functions by workers is processing return values or exceptions when they complete.Globus Compute imposes a handful of task-rate and data limits on submitted functions.
Users are responsible for authenticating via Globus and maintaining their Globus Compute endpoints on their target systems.
Users can still define Executor instances within their user functions and submit MPI applications normally, as long as libEnsemble and the target application are accessible on the remote system:
# Within remote user function
from libensemble.executors import MPIExecutor
exctr = MPIExecutor()
exctr.register_app(full_path="/home/user/forces.x", app_name="forces")
task = exctr.submit(app_name="forces", num_procs=64)
Specify a Globus Compute endpoint in sim_specs via the globus_compute_endpoint
argument. For example:
from libensemble.specs import SimSpecs
sim_specs = SimSpecs(
sim_f = sim_f,
inputs = ["x"],
out = [("f", float)],
globus_compute_endpoint = "3af6dc24-3f27-4c49-8d11-e301ade15353",
)
See the libensemble/tests/scaling_tests/globus_compute_forces directory for a complete
remote-simulation example.
Instructions for Specific Platforms¶
The following subsections have more information about configuring and launching libEnsemble on specific HPC systems.